
Predictable updating about AI risk
How worried about AI risk will we feel when we can see AGI up close? We should worry accordingly now.

(Podcast version here, or search “Joe Carlsmith Audio” on your podcast app.)
"This present moment used to be the unimaginable future."
- Stewart Brand
1. Introduction
Here’s a pattern you may have noticed. A new frontier AI, like GPT-4, gets released. People play with it. It’s better than the previous AIs, and many people are impressed. And as a result, many people who weren’t worried about existential risk from misaligned AI (hereafter: “AI risk”) get much more worried.1
Now, if these people didn’t expect AI to get so much better so soon, such a pattern can make sense. And so, too, if they got other unexpected evidence for AI risk – for example, concerned experts signing letters and quitting their jobs.
But if you’re a good Bayesian, and you currently put low probability on existential catastrophe from misaligned AI (hereafter: “AI doom”), you probably shouldn’t be able to predict that this pattern will happen to you in the future.2 When GPT-5 comes out, for example, it probably shouldn’t be the case that your probability on doom goes up a bunch. Similarly, it probably shouldn’t be the case that if you could see, now, the sorts of AI systems we’ll have in 2030, or 2050, that you’d get a lot more worried about doom than you are now.
But I worry that we’re going to see this pattern anyway. Indeed, I’ve seen it myself. I’m working on fixing the problem. And I think we, as a collective discourse, should try to fix it, too. In particular: I think we’re in a position to predict, now, that AI is going to get a lot better in the coming years. I think we should worry, now, accordingly, without having to see these much-better AIs up close. If we do this right, then in expectation, when we confront GPT-5 (or GPT-6, or Agent-GPT-8, or Chaos-GPT-10) in the flesh, in all the concreteness and detail and not-a-game-ness of the real world, we’ll be just as scared as we are now.
This essay is about what “doing this right” looks like. In particular: part of what happens, when you meet something in the flesh, is that it “seems more real” at a gut level. So the essay is partly a reflection on the epistemology of guts: of visceral vs. abstract; “up close” vs. “far away.” My views on this have changed over the years: and in particular, I now put less weight on my gut’s (comparatively skeptical) views about doom.
But the essay is also about grokking some basic Bayesianism about future evidence, dispelling a common misconception about it (namely: that directional updates shouldn’t be predictable in general), and pointing at some of the constraints it places on our beliefs over time, especially with respect to stuff we’re currently skeptical or dismissive about. For example, at least in theory: you should never think it >50% that your credence on something will later double; never >10% that it will later 10x, and so forth. So if you’re currently e.g. 1% or less on AI doom, you should think it’s less than 50% likely that you’ll ever be at 2%; less than 10% likely that you’ll ever be at 10%, and so on. And if your credence is very small, or if you’re acting dismissive, you should be very confident you’ll never end up worried. Are you?
I also discuss when, exactly, it’s problematic to update in predictable directions. My sense is that generally, you should expect to update in the direction of the truth as the evidence comes in; and thus, that people who think AI doom unlikely should expect to feel less worried as time goes on (such that consistently getting more worried is a red flag). But in the case of AI risk, I think at least some non-crazy views should actually expect to get more worried over time, even while being fairly non-worried now. In particular, if you think you face a small risk conditional on something likely-but-not-certain (for example, AGI getting developed by blah date), you can sometimes expect to update towards facing the risk, and thus towards greater worry, before you update towards being safe. But there are still limits to how much more worried you can predictably end up.
Importantly, none of this is meant to encourage consistency with respect to views you held in the past, at the expense of reasonableness in the present or future. If you said .1% last year, and you’re at 10% now (or if you hit 90% when you see GPT-6): well, better to just say “oops.” Indeed, I’ve been saying “oops” myself about various things. And more generally, applying basic Bayesianism in practice takes lots of taste. But faced with predictable progress towards advanced but mostly-still-abstract-for-now AI, I think it’s good to keep in mind.
I close with some thoughts on how we will each look back on what we did, or didn’t do, during the lead-up to AGI, once the truth about the risks is made plain.
Thanks to Katja Grace for extensive discussion and inspiration. See also citations in the main text and footnotes for specific points and examples that originated with Katja. And thanks also to Leopold Aschenbrenner for comments. Some of my thinking and writing on this topic occurred in the context of my work for Open Philanthropy, but I’m speaking only for myself and not for my employer.
2. Sometimes predictably-real stuff doesn’t feel real yet
"Every year without knowing it I have passed the day
When the last fires will wave to me
And the silence will set out
Tireless traveler
Like the beam of a lightless star"
- W.S. Merwin, “For the Anniversary of My Death”
I first heard about AI risk in 2013. I was at a picnic-like thing, talking with someone from the Future of Humanity Institute. He mentioned AI risk. I laughed and said something about “like in the movie I, Robot?” He didn’t laugh.
Later, I talked with more people, and read Bostrom’s Superintelligence. I had questions, but the argument seemed strong enough to take seriously. And at an intellectual level, the risk at stake seemed like a big deal.
At an emotional level, though, it didn’t feel real. It felt, rather, like an abstraction. I had trouble imagining what a real-world AGI would be like, or how it would kill me. When I thought about nuclear war, I imagined flames and charred cities and poisoned ash and starvation. When I thought about biorisk, I imagined sores and coughing blood and hazmat suits and body bags. When I thought about AI risk, I imagined, um … nano-bots? I wasn’t good at imagining nano-bots.
I remember looking at some farmland out the window of a bus, and wondering: am I supposed to think that this will all be compute clusters or something? I remember looking at a church and thinking: am I supposed to imagine robots tearing this church apart? I remember a late night at the Future of Humanity Institute office (I ended up working there in 2017-18), asking someone passing through the kitchen how to imagine the AI killing us; he turned to me, pale in the fluorescent light, and said “whirling knives.”
Whirling knives? Diamondoid bacteria? Relentless references to paper-clips, or “tiny molecular squiggles”? I’ve written, elsewhere, about the “unreality” of futurism. AI risk had a lot of that for me.
That is, I wasn’t viscerally worried. I had the concepts. But I didn’t have the “actually” part. And I wasn’t alone. As I started working on the topic more seriously, I met some people who were viscerally freaked-out, depressed, and so on – whether for good or ill. But I met lots of people who weren’t, and not because they were protecting their mental health or something (or at least, not very consciously). Rather, their head was convinced, but not their gut. Their gut still expected, you know, normality.
At the time, I thought this was an important signal about the epistemic situation. Your gut can be smarter than your head. If your gut isn’t on board, maybe your head should be more skeptical. And having your gut on board with whatever you’re doing seems good from other angles, too.3 I spent time trying to resolve the tension. I made progress, but didn’t wholly sync up. To this day, nano-bots and dyson spheres and the word “singularity” still land in an abstract part of my mind – the part devoted to a certain kind of conversation, rather than to, like, the dirty car I can see outside my window, and the tufts of grass by the chain-link fence.
I still think that your gut can be an important signal, and that if you find yourself saying that you believe blah, but you’re not feeling or acting like it, you should stop and wonder. And sometimes, people/ideas that try to get you to not listen to your gut are trying (whether intentionally or not) to bypass important defenses. I am not, in what follows, trying to tell you to throw your gut away. And to the extent I am questioning your gut: please, by all means, be more-than-usually wary. Still, though, and speaking personally: I’ve come to put less stock than I used to in my gut’s Bayesian virtue with respect to AI. I want to talk a bit about why.
3. When guts go wrong
"Then I will no longer
Find myself in life as in a strange garment
Surprised at the earth…"
-W.S. Merwin, “For the Anniversary of My Death”
Part of this is reflection on examples where guts go wrong, especially about the future. There are lots of candidates. Indeed, depending on how sharply we distinguish between your “system 1” and your gut, a lot of the biases literature can be read as anti-gut, and a lot of early rationalism as trying to compensate. My interest in head-gut agreement was partly about trying to avoid overcorrection. But there is, indeed, something to be corrected. Here are two examples that seem relevant to predictable updating.
3.1 War
“Abstraction is a thing about your mind, and not the world… Saying that AI risk is abstract is like saying that World War II is abstract, because it’s 1935 and hasn’t happened yet. If it happens, it will be very concrete and bad. It will be the worst thing that has ever happened.”
I think Katja’s war example is instructive. Consider some young men heading off to war. There’s a trope, here, about how, when the war is just starting, some men sign up excitedly, with dreams of glory and honor. Then, later, they hit the gritty reality: trenches, swamps, villages burning, friends gasping and gurgling as they die. Ken Burn’s Vietnam War documentary has some examples. See also “Born on the Fourth of July.” The soldiers return, if they return, with a very different picture of war. “In all my dreams before my helpless sight/ He plunges at me, guttering, choking, drowning…”

Stretcher bearers in World War I (source here)
{kind=link}
Now, a part of this is that their initial picture was wrong. But also, sometimes, it’s that their initial picture was abstract. Maybe, if you’d asked them ahead of time, they’d have said “oh yeah, I expect the trenches to be very unpleasant, and that I will likely have to watch some of my friends die.” But their gut didn’t expect this – or, not hard enough. Surrounded, when they set out, by flags and smiling family members and crisp uniforms, it’s hard to think, too, of flies in the eyes of rotting corpses; or trench-foot, and the taste of mustard gas. And anyway, especially if you’re heading into a very new context, it’s often hard to know the specifics ahead of time, and any sufficiently-concrete image is predictably wrong.
I worry that we’re heading off to something similar, epistemically, to a new war, with respect to AI risk.4 Not: happily, and with dreams of glory. But still: abstractly. We’re trying to orient intellectually, and to do what makes sense. But we aren’t in connection with what it will actually be like, if AI kicks off hard, and the doomers are right. Which isn’t to say it will be trench foot and mustard gas. Indeed, even if things go horribly wrong eventually, it might actually be awesome in lots of ways for a while (even if also: extremely strange). But whatever it will be, will be a specific but very-different-from-now thing. Guts aren’t good at that. So it’s not, actually, all that surprising if you’re not as viscerally worried as your explicit beliefs would imply.
3.2 Death
"And who by fire, who by water
Who in the sunshine, who in the night time
Who by high ordeal, who by common trial…"
Another famous example here is death. No one knows the date or hour. But we know: someday.5 Right? Well, sort of. We know in the abstract. We know, but don’t always realize. And then sometimes we do, and some vista opens. We reel in some new nothingness. Something burns with new preciousness and urgency.
And sometimes this happens, specifically, when “someday, somehow” becomes “soon, like this.” When the doctor tells you: you, by avalanche. You, by powder. The month of May. Slow decay. Suddenly, when you’re actually looking at the scans, when you’re hearing estimates in months, you learn fresh who is calling; and despite having always known, some sort of “update” happens. Did the gut not fully believe? One’s own death, after all, is hard to see.
I’ve written about this before. Tim McGraw has a song about the scans thing. “Live like you were dying.” I’m trying. I’m trying to think ahead to that undiscovered hospital. I’m trying to think about what I will take myself to have learned, when I walk out into the parking lot, with only months to live. I’m trying to learn it now instead.
Really, this is about predictable updating. The nudge in McGraw’s title – you’re already dying – is Bayesian. You shouldn’t need the scans. If you know, now, what you’ll learn later, you can learn it now, too. Death teaches unusually predictable lessons – about fleetingness, beauty, love. And unusually important lessons, too. Bayes bites, here, with special gravity. But there’s some sort of gut problem. The question is how to learn hard enough, and in advance. “And not, when I come to die, to discover that I have not lived.”
Importantly, though: if your gut thinks you’re not going to die, it’s not actually much evidence. Has your gut been keeping up with the longevity literature? Does it have opinions about cryopreservation? Futurism aside, the gut’s skepticism, here, is an old mistake. And we have practices. Go smear some ashes on your forehead. Go watch some birds eat a corpse. Go put some fruit on the ofrenda, or some flowers on your grandfather’s grave. Realization is an art distinct from belief. Sometimes, you already know. Religion, they say, is remembering.

Tibetan sky burial. (Source here.)
{kind=link}
4. Noticing your non-confusion
So these are some examples where “but my gut isn’t in a very visceral relationship with blah” just isn’t a very strong signal that blah is false. But I also want to flag some more directly AI related places where I think something gut-related has been messing up, for me.
4.1 LLMs
ChatGPT caused a lot of new attention to LLMs, and to AI progress in general. But depending on what you count: we had scaling laws for deep learning back in 2017, or at least 2020. I know people who were really paying attention; who really saw it; who really bet. And I was trying to pay attention, too. I knew more than many about what was happening. And in a sense, my explicit beliefs weren’t, and should not have been, very surprised by the most recent round of LLMs. I was not a “shallow patterns” guy. I didn’t have any specific stories about the curves bending. I expected, in the abstract, that the LLMs would improve fast.
But still: when I first played with one of the most recent round of models, my gut did a bunch of updating, in the direction of “oh, actually,” and “real deal,” and “fire alarm.” Some part of me was still surprised.
Indeed, noticing my gut (if not my head) getting surprised at various points over the past few years, I’ve realized that my gut can have some pretty silly beliefs about AI, and/or can fail to connect fairly obvious dots. For example, when I first started thinking about AI, I think some part of me failed to imagine that eventually, if AIs got smart enough, we could just talk to them, and that they would just understand what we were saying, and that interacting with them wouldn’t necessarily be some hyper-precise coding thing. I had spoken to Siri. Obviously, that didn’t count. Then, one day, I spoke, with my voice, to a somewhat-smarter AI, and it responded in a very human-sounding voice, and it was much more like talking on the phone, and some sort of update happened.
Similarly: I think that in the past, I failed to imagine what the visual experience of interacting with an actually-smart AI would be like. Obviously, I knew about robots; HAL’s red stare; typing commands into a terminal; texting. But somehow, old talk of AGI didn’t conjure this for me. I’m not sure what it conjured. Something about brains in boxes, except: laptops? I think it wasn’t much of anything, really. I think it was just a blank. After all, this isn’t sci-fi. So it must not be like anything you’d see in sci-fi, either, including strains aimed at realism. People, we’re talking about the real future, which means something unimaginable, hence fiction to the imagination, hence nothingness. “The future that can be named is not the true future.” Right?
Wrong. “Named super specifically” is more plausible, but even wariness of specificity can mislead: sometimes, even the specifics are pretty obvious. I had seen Siri, and chat bots. What sort of fog was I artificially imposing on everything? What was so hard about imagining Siri, but smarter? Now, it feels like “oh, duh.” And certain future experiences feel more concrete, too. It now feels like: oh, right, lots of future AIs will probably have extremely compelling and expressive digital human avatars. Eventually (soon?), they’ll probably be able to look just like (super-hot, super-charismatic) humans on zoom calls. What did I think it would be, R2D2?

“Oh, duh” is never great news, epistemically. But it’s interestingly different news than “noticing your confusion,” or being straightforwardly surprised. It’s more like: noticing that at some level, you were tracking this already. You had the pieces. Maybe, even, it’s just like you would’ve said, if you’d been asked, or thought about it even a little. Maybe, even, you literally said, in the past, that it would be this way. Just: you said it with your head, and your gut was silent.
I mentioned this dynamic to Trevor Levin, and he said something about “noticing your non-confusion.” I think it’s a good term, and a useful skill. Of course, you can still update upon seeing stuff that you expected to see, if you weren’t certain you’d see it. But if it feels like your head is unconfused, but your gut is updating from “it’s probably fake somehow” to “oh shit it’s actually real,” then you probably had information your gut was failing to use.
4.2 Simulations
I’ll give another maybe-distracting example here. Last year, I spent some time thinking about whether we live in a computer simulation. It’s a strange topic, but my head takes the basic argument pretty seriously. My gut, though, generally thinks it’s fake somehow, and forgets about it easily.
I remember a conversation I had with a friend sometime last year. He said something like: “you know, pretty soon, all sorts of intelligent agents on earth are going to be living in simulations.” I nodded or something. It’s like how: if the scientists are actually putting people’s brains in vats, it’s harder to stamp your foot and say “no way.” We moved on.
Then, in early April, this paper came out: “Generative Agents: Interactive Simulacra of Human Behavior.” They put 25 artificial agents into an environment similar to The Sims, and had them interact, including via e.g. hosting a valentine’s day party.6 Here’s the picture from the paper:

From here.
I opened this paper, read the beginning, looked at this picture, and felt my gut update towards being in a sim. But: c’mon now, gut! What sort of probability would I have put, last year, on “I will, in the future, see vaguely-smart artificial agents put into a vaguely-human simulated environment”? Very high. My friend had literally said as much to me months earlier, and I did not doubt. Indeed, what’s even the important difference between this paper and AlphaStar, or the original Sims?7How smart the models are? The fact that it’s cute and human-like? My gut lost points, here.
It’s an avoidable mistake. I’m trying to stop making it.
I worry that we’re in for a lot of dynamics like this. How seriously, for example, are you taking the possibility that future AIs will be sentient? Well, here’s a mistake to not make: updating a lot once the AIs are using charismatic human avatars, or once they can argue for their sentience as convincingly as a human. Predict it now, people. Update now.
4.3 “It’s just like they said”
I don’t, often, have nightmares about AI risk. But I had one a few months ago. In it, I was at a roll-out of some new AI system. It was a big event, and there were lots of people. The AI was unveiled. Somehow, it immediately wrote each one of us some kind of hyper-specific, individualized message, requiring a level of fine-grained knowledge and predictive ability that was totally out of the question for any familiar intelligence. I read my message and felt some cold and electric bolt, some recognition. I thought to myself: “it’s just like they said.” I looked around me, and the room was in chaos. Everything was flying apart, in all directions. I don’t remember what happened after that.
“Just like they said.” Who’s they? Presumably, the AI worriers. The ones who think that superintelligence is not a fantasy or a discussion-on-twitter, but an actual thing we are on track to do with our computers, and which will cut through our world like butter if we get it wrong.
But wait: aren’t I an AI worrier? More than many, at least. But dreams, they say, are partly the gut’s domain. Perhaps the “they,” here, was partly my own explicit models. Ask me in the waking world: “will superintelligence be terrifying?” Yes, of course, who could doubt. But ask in my dreams instead, and I need to see it up close. I need to read the message. Only then will my gut go cold: “Oh, shit, it’s just like they said.”
I’ve had this feeling a few times in the past few months. I remember, a few years ago, making a simple model of AI timelines with a colleague. We used a concept called “wake-up,” indicating the point where the world realized what was happening with AI and started to take it seriously. I think that if, at that point, we could’ve seen what things would be like in 2023, we would’ve said something like: “yeah, that” (though: there’s a ton more waking up to do, so future wake-ups might end up better candidates).
Similarly, “they” have worried for ages about triggering or exacerbating “race dynamics” in AI. Then, in recent months, Google went into a “Code Red” about AI, and the CEO of Microsoft came out and just said straight up: “the race starts today.”
“They” have worried about AIs being crazy alien minds that we don’t understand. Then, in February, we got to see, briefly, the rampaging strangeness of a good Bing – including all sorts of deception and manipulation and blackmail, which I don’t actually think is the centrally worrying kind, but which doesn’t exactly seem like good news, either.
“They” have worried about agents, and about AIs running wild on the internet, and about humans not exactly helping with that. Now we have Auto-GPT, and Chaos-GPT, and I open up my browser and I see stuff like this:

Not the pixels I wanted to be seeing at this point in my life.
Now, I don’t want to litigate, here, exactly who “called” what (or: created what8), and how hard, and how much of an update all this stuff should be. And I think some things – for example, the world’s sympathy towards concern about risks from AI – have surprised some doomers, however marginally, in the direction of optimism. But as someone who has been thinking a lot about AI risk for more than five years, the past six months or so have felt like a lot of movement from abstract to concrete, from “that’s what the model says” to “oh shit here we are.” And my gut has gotten more worried.
Can this sort of increased worry be Bayesian? Maybe. I suspect, though, that I’ve just been messing up. Let’s look at the dynamics in more detail.
5. Smelling the mustard gas
"Men marched asleep…
All went lame, all blind."
It’s sometimes thought that, as a Bayesian, you shouldn’t be able to predict which direction you’ll update in the future.9 That is, if you’re about to get some new evidence about p, you shouldn’t be able to predict whether this evidence will move your credence on p higher or lower. Otherwise, the thought goes, you could “price in” that evidence now, by moving your credence in the predicted direction.
But this is wrong.10 Consider a simple example. Suppose you’re at 99% that Trump won the election. You’re about to open the newspaper that will tell you for sure. Here, you should be at 99% that you’re about to increase your credence on Trump winning: specifically, up to 100%. It’s a very predictable update.
So why can’t you price it in? Because there’s a 1% chance that you’re about to lower your confidence in Trump winning by a lot more: specifically, down to 0%. That is, in expectation, your confidence in Trump winning will remain the same.11 And it’s the expectation of your future update that Bayesian binds.
To understand this more visually, let’s use a slightly more complicated example. Suppose you’re currently at 80% that GPT-6 is going to be “scary smart,” whatever that means to you. And suppose that, conditional on GPT-6 being scary smart, your probability on AI doom is 50%; and conditional on GPT-6 not being scary smart, your probability on AI doom is 10%. So your credence looks like this:
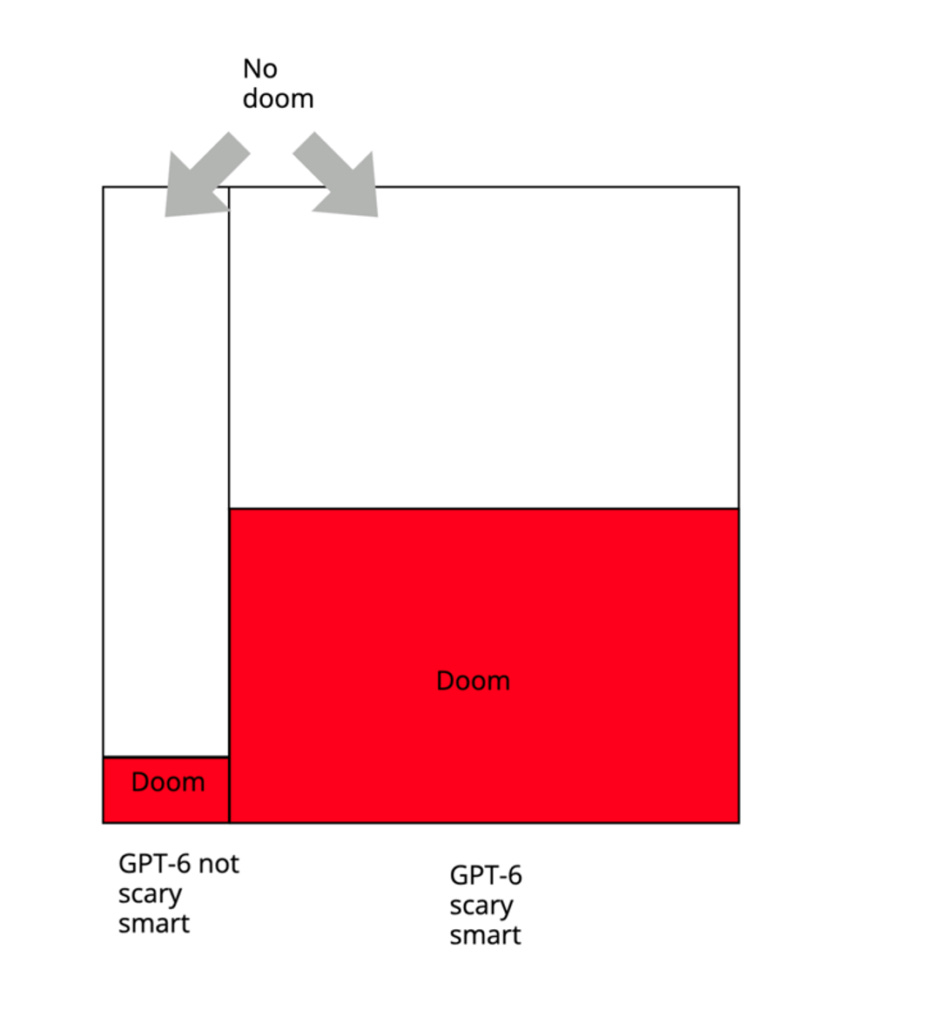
Now, what’s your overall p(doom)? Well, it’s:
(probability that GPT-6 is scary smart * probability of doom conditional on GPT-6 being scary smart) + (probability that GPT-6 isn’t scary smart * probability of doom conditional on GPT-6 not being scary smart)
That is, in this case, 42%.12
But now we can see a possible format for a gut-problem mistake. In particular: suppose that I ask you, right now, surrounded by flags and crisp uniforms, about the probability of doom. You query your gut, and it smells no mustard gas. So you give an answer that doesn’t smell much mustard gas, either. Let’s say, 10%. And let’s say you don’t really break things down into: OK, how much mustard gas do I smell conditional on GPT-6 being scary smart, vs. not, and what are my probabilities on that.13 Rather, your model is an undifferentiated mass:

Or maybe you do try to break things down like that, but the waft of the gas fades with all the distance. GPT-6 is far away, behind some fog. Still: you guess, with your head, and without your gut participating, that p(doom) is indeed a bit higher conditional on GPT-6 being scary smart, what with the update towards “short timelines.” Let’s say, 20%; and 10% otherwise. So maybe your overall p(doom), given 80% on the abstract idea of GPT-6 being scary smart, is 18%.

But actually, let’s say, if you could see a “scary smart” GPT-6 model right now, you would freak out way harder. You would be able to smell the gas up close, that bitter tang. Your gut would get some message, and come alive, and start participating in the exercise. “That thing,” your gut might say, “is scary. I’m at 50% on doom, now.”
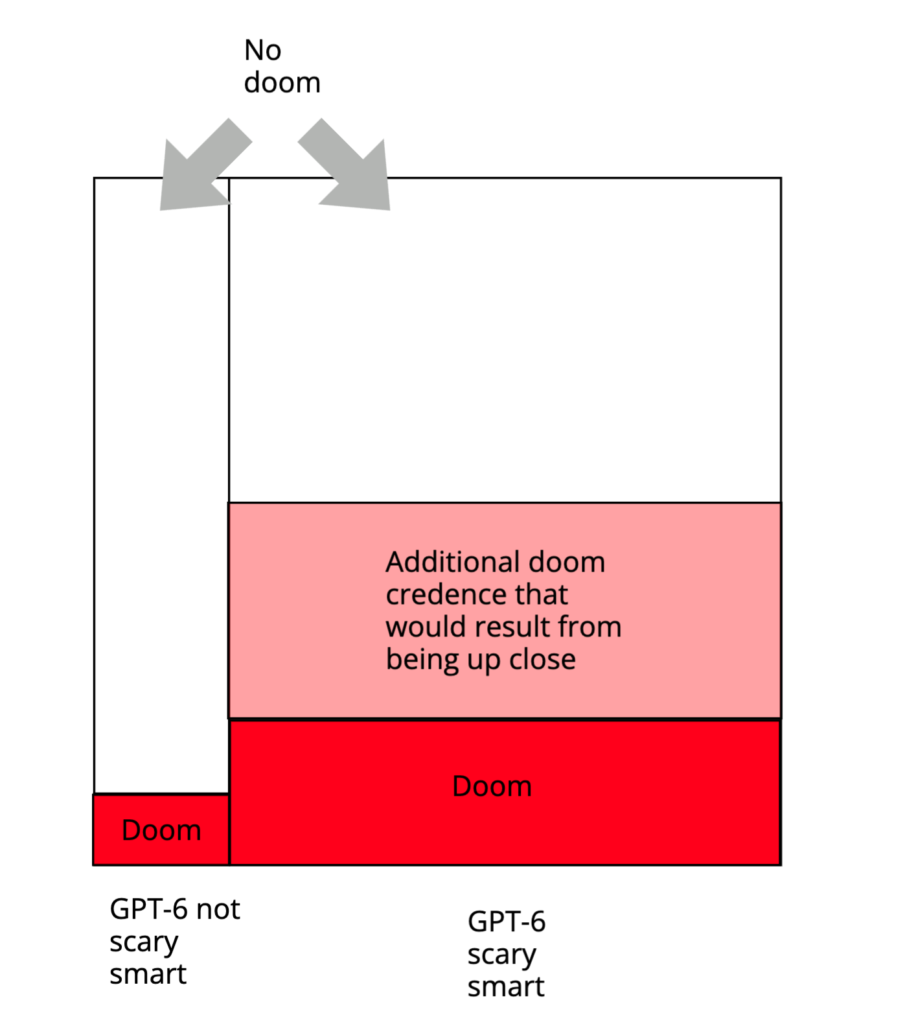
Thus, you end up inconsistent, and dutch-bookable (at least in principle – setting aside issues re: betting on doom). Suppose I ask you, now, to agree to sell me a “pays out $100 conditional on doom” ticket for $30 (let’s assume this can actually pay out), conditional on GPT-6 being scary smart. You’re only at 20% doom in such a world, so you predict that such a ticket will only be worth $20 to you if this deal is ever triggered, so you agree. But actually, when we get to that world, your gut freaks out, and you end up at 50% doom, and that ticket is now worth $50 to you, but you’re selling it for $30. Plus, maybe now you’re regretting other things. Like some of those tweets. And how much alignment work you did.
As indicated above, I think I’ve made mistakes in this vein. In particular: a few years back, I wrote a report about AI risk, where I put the probability of doom by 2070 at 5%. Fairly quickly after releasing the report, though, I realized that this number was too low.14 Specifically, I also had put 65% on relevantly advanced and agentic AI systems being developed by 2070. So my 5% was implying that, conditional on such systems being developed, I was going to look them in the eye and say (in expectation): “~92% that we’re gonna be OK, x-risk-wise.” But on reflection, that wasn’t, actually, how I expected to feel, staring down the barrel of a machine that outstrips human intelligence in science, strategy, persuasion, power; still less, billions of such machines; still less, full-blown superintelligence. Rather, I expected to be very scared. More than 8% scared.
5.1 Should you trust your future gut, though?
Now, you might wonder: why give credit to such future fear?15 After all, isn’t part of the worry about doomers that they’re, you know, fraidy-cats? Paranoids? (C’mon: it’s just a superintelligent machine, the invention of a second advanced species, the introduction of a qualitatively new order of optimization power into earth’s ecosystem. It’s just, you know, change.) And isn’t the gut, famously, a bit skittish? Indeed, if you’re worried about your gut being underactive, at a distance, shouldn’t you also be worried about it being over-active, up close? Shouldn’t you reason, instead, ahead of time, at a distance, and in a cool hour, about how scared you should be when you’re there-in-person?
Well, it’s a judgment call. Sometimes, indeed, at-a-distance is a better epistemic vantage point than up-close. Especially if you know yourself to have biases. Maybe, for example, you’ve got a flying phobia, and you know that once you’re on the plane, your gut’s estimates of the probability of the plane crashing are going to go up a lot. Should you update now, then? Indeed: no.
But, personally, with respect to the future, I tend to trust my future self more. It’s a dicey game already, futurism, and future Joe has a lot more data. The future is a foreign country, but he’s been there.
And I tend to trust my up-close self more, in general, for stuff that requires realization rather than belief (and I think words like “superintelligence” require lots of realization). Maybe the journalist has the accurate casualty count; but I trust the soldier on the ground to know what a casualty means. And I trust the man with the scans about death.
Now, importantly, there’s also a thing where guts sometimesreact surprisingly little, up close, to AI stuff you predicted ahead of time you’d be scared about. Part of this is the “it’s not real AI if you can actually do it,” thing (though, my sense is that this vibe is fading?). Part of it is that sometimes, machines doing blah (e.g., beating humans at chess) is less evidence about stuff than you thought. And I wonder if part of it is that sometimes, your at-a-distance fear of that futuristic AI stuff was imagining some world less mundane and “normal” than the world you actually find yourself in, when the relevant stuff comes around — such that when you, sitting in your same-old apartment, wearing your same-old socks, finally see AIs planning, or understanding language, or passing two-hour human coding interviews in four minutes, or winning the IMO, it feels/will feel like “well that can’t be the scary thing I had in mind, because that thing is happening in the real world actually and I still have back pain.”16 At the least, we get used to stuff fast.
GPT-4 doing a coding interview. From here.
Still: sometimes, also, you were too scared before, and your gut can see that now. And there, too, I tend to think your earlier self should defer: it’s not that, if your future self is more scared, you should be more scared now, but if your future self is less scared, you should think that your future self is biased. Yes requires the possibility of no. If my future self looks the future AGI in the eye and feels like “oh, actually, this isn’t so scary after all,” that’s evidence that my present self is missing something, too. Here’s hoping.
5.2 An aside on mental health
Now: a quick caution. Here I’ve been treating guts centrally from an epistemic perspective. But we need a wise practical relationship with our guts as well. And from a practical perspective, I don’t think it’s always productive to try to smell mustard gas harder, or to make horrible things like AI doom vivid. The right dance here is going to vary person-to-person, and I won’t try to treat the topic now (though: see here for a list of resources). But I wanted to flag explicitly that staying motivated and non-depressed and so forth, in relation to a pretty scary situation, is a separate art, and one that needs to be woven carefully with the more centrally epistemic angle I’m focused on here.
6. Constraints on future worrying
Returning to the epistemic perspective though: let’s suppose you do trust your future credences, and you want to avoid the Bayesian “gut problems” I discussed above. In that case, at least in theory, there are hard constraints on how you should expect your beliefs to change over time, even as you move from far away to up close.
In particular, you should never think that there’s more than a 1/x chance that your credence will increase by x times: i.e., never more than a 50% chance that it’ll double, never more than a 10% chance that it’ll 10x. And if your credence is very small, then even very small additive increases can easily amount to sufficiently substantive multiplicative increases that these constraints bite. If you move from .01% to .1%, you’ve only gone up .09% in additive terms – only nine parts in ten thousand. But you’ve also gone up by a factor of 10 – something you should’ve been at least 90% sure would never happen.
So suppose that right now, you identify as an “AI risk skeptic,” and you put the probability of doom very low. For concreteness, suppose that you like David Thorstad’s number: .00002% — that is, one in five million (though: he now thinks this “too generous” – and he’s also “not convinced that we are in a position where estimating AI risk makes good methodological sense,” which I suspect is a bigger crux). This is a very low number. And it implies, in particular, that you really don’t expect to get even a small amount more worried later. For example, you need to have a maximum of .01% that you ever see evidence that puts the probability at >.2%.
Now suppose that a few years pass, GPT-6 comes out, and lo, indeed, it is very impressive. You look GPT-6 in the eye and you feel some twinge in your gut. You start to feel a bit, well, at-least-1-percent-y. A bit not-so-crazy-after-all. Now, admittedly, you were probably surprised that GPT-6 is so good. You were a “timelines skeptic,” too. But: how much of a skeptic? Were you, for example, less than one in fifty thousand that GPT-6 would be this impressive? That’s what your previous number can easily imply, if the impressiveness is what’s driving your update.
And now suppose that actually, you weren’t much of a timelines skeptic at all. GPT-6, according to you, is right on trend. You’d seen the scaling laws. You were at >50% on at-least-this-impressive. It was predictable. It’s just that the rest of the argument for doom is dumb.
In that case, though, hmm. Your gut’s got heavy constraints, in terms of twinging. >50% on at least-this-impressive? So: you’re still supposed to be at less than .00004% on doom? But what if you’re not…
Or maybe you think: “the argument for doom has not been satisfactorily peer-reviewed. Where’s the paper in Nature? Until I see conventional academic signals, I am at less than one in a thousand on doom, and I shall tweet accordingly.” OK: but, the Bayesianism. If you’re at less than one in a thousand, now, and your big thing is academic credibility, where should Bayes put you later, conditional on seeing conventional academic signals? And what’s your probability on such strange sights? In five years, or ten years, are you confident there won’t be a paper in Nature, or an equivalent? If it’s even 10% percent likely, and it would take you to more than 1%, your number now should be moving ahead of time.
Or maybe you thought, in the past: “until I see the experts worrying, I’m at less than 1%.” Well, here we are (here we already were, but more now). But: what was your probability that we ended up here? Was it so hard to imagine, the current level of expert sympathy? And are future levels of greater sympathy so hard to imagine, now? It’s easy to live, only, in the present – to move only as far as the present has moved. But the Bayesian has to live, ahead of time, in all the futures at once.
(Note that all of these comments apply, symmetrically, to people nearly certain of doom. 99.99%? OK, so less than 1% than you ever drop to 99% or lower? So little hope of future hope?)
Now: all of this is “in theory.” In practice, this sort of reasoning requires good taste. I talk about such taste more below. First, though, I want to look at the theory a bit more.
7. Should you expect low probabilities to go down?
Above I said that actually, the direction of a future update is often predictable. But notice: which direction should you predict? My sense is that in many evidential situations (though not all – more below), you should think your future evidence more likely to move you in the right direction than the wrong one. So if you think that p is likely to be true, you should generally think that your future evidence is likely to update you towards higher credence on p. And vice versa: if you think that p is more likely to be false, you should expect to have lower credence on it later.
The Trump example above is an extreme case. You’re at 99% on Trump winning, and you’re also at 99% that you’ll update, in future, towards higher credence on Trump winning. And we can imagine a more intermediate case, where, let’s say, you’re at 90% that Trump is going to win, and you’re about to watch the presidential debate, and you think that winning the debate is highly correlated with winning the election. Which direction should you predict that your credence on Trump winning will move, once the debate is over? Given that you think Trump is likely to win the election, I think you should think he’s likely to win the debate, too. And if he wins the debate, your credence on him winning the election will go up (whereas if he loses, it’ll go down a bunch more).
Or consider a scientist who doesn’t believe in God. In principle, at each moment, God could appear before her in a tower of flames. She has some (very small) credence on this happening. And if it happened, she would update massively towards theism. But absence of evidence is evidence of absence. Every moment she doesn’t observe God appearing before her in a tower of flames, she should be updating some tiny amount towards atheism. And because she predicts very hard that God will never appear before her in a tower of flames, she should be predicting very hard that she will become a more and more confident atheist over time, and that she’ll die with even less faith than she has now.

Updating so hard right now… (Image source here.)
{kind=link}
So too, one might think, with AI risk. If you are currently an AI risk skeptic, plausibly you should expect to become more and more confidently skeptical over time, as your remaining uncertainties about the case for non-doom get resolved in the direction of truth. That is, every moment that the superintelligent machines don’t appear before you in a tower of diamondoid bacteria (that’s the story, right?), then anthropic effects aside, you should be breathing easier and easier. Or, more realistically, you should be expecting to see, well, whatever it is that comforts you: i.e., that we’ll hit another AI winter; or that we’ll make lots of progress in mechanistic interpretability; or that innovations in RLHF will allow superhuman oversight of AI behavior humans can’t understand; or that we won’t see any signs of deception or reward hacking; or that progress will be slow and gradual and nicely coordinated; or that we’ll finally, finally, get some peer review, and put the must-be-confusions to rest. And as your predictions are confirmed, you should be feeling safer and safer.
Is that what you expect, in your heart? Or are you, perhaps, secretly expecting to get more worried over time? I wished I’d asked myself harder. In particular: my 5% was plausibly implying some vibe like: “sure, there are these arguments that superintelligent AI will disempower us, and I give them some weight, but at least if we’re able to think well about the issue and notice the clues that reality is giving us, over time it will probably become clearer that these arguments are wrong/confused, and we’ll be able to worry much less.” Indeed, depending on the volatility of the evidence I was expecting, perhaps I should have thought that I was likely to be in the ballpark of the highest levels of worry about doom that I would ever endorse. But if you’d asked me, would I have said that?
That said, I actually think these dynamics are more complicated than they might initially seem. In particular, while I find it plausible that you should generally predict that you’ll update in the direction of what you currently expect to be true, sometimes, actually, you shouldn’t. And some non-crazy views on AI risk fit the mold.
Katja Grace suggested to me some useful examples. Suppose that you’re in a boat heading down a river. You at 80% that there’s a waterfall about two miles down, but 20% that there isn’t, and that you’re going to see a sign, a mile down, saying as much (“No waterfall” – classic sort of sign). Conditional on no sign/there being a waterfall, you’re at 10% that it’s a big waterfall, which will kill you, and 90% that it’s a small waterfall, which you’ll survive. So currently, your credence on dying is 8%. However, you’re also at 80% that in a mile, it’s going to go up, to 10%, despite your also predicting, now, that this is an update towards higher credence on something that probably won’t happen.
Or a consider a more real-world example (also from Katja). At 3 pm, you’re planning to take a long car trip. But there’s a 10% chance the trip will fall through. If you take the trip, there’s some small chance you get in an accident. As you approach 3 pm, your credence in “I will get in a car accident today” should go up, as the trip keeps (predictably) not-falling-through. And then, as you’re driving, it should go down gradually, as the remaining time in the car (and therefore, in danger) shrinks.
Some views on AI – including, skeptical-of-doom views – look like this. Suppose, for example, you think AGI-by-2070 more likely than not. And suppose that conditional on AGI-by-2070, you think there’s some small risk that the doomers are right, and we all die. And you think it’s going to be hard to get good evidence to rule this out ahead of time. Probably, though, we’ll make it through OK. And conditional on no-AGI-by-2070, you think we’re almost certainly fine. Here, you should plausibly expect to get more worried over time, as you get evidence confirming that yes, indeed, AGI-by-2070; yes, indeed, waterfall ahead. And then to get less worried later, as the waterfall proves small.
That said, this sort of dynamic requires specific constraints on what evidence is available, when. The truth about the future must fail to leak backwards into the past. You must be unable to hear the difference between a big waterfall and a small waterfall sufficiently ahead-of-time. The gas ahead must not waft.
Car accidents are indeed like this. People rarely spend much time with high credence that they’re about to get in a car accident. Their probability is low; and then suddenly it jumps wildly, split-second high, before death, or some bang-crunch-jerk, or a gasping near-miss.
Is AI risk like this too? Doomers sometimes talk this way. You’ll be cruising along. Everything will be looking rosy. The non-doomers will be feeling smug. Then suddenly: bam! The nanobots, from the bloodstream, in the parlor, Professor Plum. The clues, that is, didn’t rest on the details. A lot of it was obvious a priori. You should’ve read more LessWrong back in the 2000s. You should’ve looked harder at those empty strings.
Now, sometimes this sort of vibe seems to me like it wants to have things both ways. “I shall accept ahead-of-time empirical evidence that I am right; but in the absence of such evidence, I shall remain just as confident.” “My model makes no confident predictions prior to the all-dropping-dead thing – except, that is, the ones that I want to claim credit for after-the-fact.” Here I recall a conversation I overheard back in 2018 about “optimization daemons” (now: mesa-optimizers, goal mis-generalization, etc) in which a worrier said something like: “I will accept empirical arguments for concern, but only a priori arguments for comfort.” It was an offhand remark, but still: not how it works.
However: I do think, unfortunately, there are risks of gas that doesn’t waft well; “King Lear problems”; risks of things looking fairly fine, right before they are very non-fine indeed. But not all the gas is like this. We should expect to get clues (indeed, we should dig hard for them). So we should expect, at some point, to start updating in the right direction. But I think it’s an open question how the sequencing here works, and it’ll depend on the details driving your particular view. In general, though, if you’re currently at more-likely-than-not on hitting an AGI waterfall sometime in the coming decades, but not certain, then prima facie, and even if your p(doom) is low, that’s reason to expect to get more worried as that soothing sign – “AI winter,” “It was all fake somehow” (classic sign) – fails to appear.
That said, even if you’re getting predictably more worried, there are still Bayesian constraints on how much. In the waterfall case, you go up 2%; in the car case, something tiny. So if you’re finding yourself, once you don’t see the sign, jumping to 50% on “death by big waterfall” – well, hmm, according to your previous views, you’re saying that you’re in a much-more-worrying-than-average not-seeing-the-sign scenario. Whence such above-average-worrying? Is the evidence you’re seeing now, re: big-waterfall, actually surprising relative to what you expected before? Looks a lot like the predicted river to me. Looks, indeed, “just like they said.” Or did your gut, maybe, not really believe …
8. Will the next president be a potato?
OK, that was a bunch of stuff about basic Bayesian belief dynamics. And armed with this sort of relatively crisp and simple model, it can be easy to start drawing strong conclusions about how you, with your mushy monkey brain, should be reasoning in the practice, and what sorts of numbers should be coming out of your mouth, when you make number-noises.
But the number-noise game takes taste. It’s a new game. We’re still learning how to play well, and productively. And I think we should be wary of possible distortions, especially with respect to small-probabilities.
Consider, for example, the following dialogue:
Them: What’s your probability that the next president is a potato?
You: What?
Them: A potato. Like, a normal potato. Up there getting inaugurated and stuff.
You: Umm, very low?
Them: Say a number!
You: [blank stare]
Them: You are a Bayesian and must have a number, and I demand that you produce it. Just literally say any number and I will be satisfied.
You: Fine. One in 10^50.
Them: What? Really? Wow that’s so stupid. I can’t believe you said that.
You: Actually, let’s say one in 10^40.
Them: Wait, your number was more than a billion times lower a second ago. If you were at one in 10^50 a second ago, you should’ve been at less than one-in-a-billion that you’d ever move this high. Is the evidence you’ve got since then so surprising? Clearly, you are a bad Bayesian. And I am clever!
You: This is a dumb thing.

Not like this: a normal potato.

Closer…
The “them” vibe, here, seems dubiously helpful. And in particular, in this case, it’s extra not-helpful to think of “you” as changing your probabilities, from one second to the next, by updating some fully-formed probability distribution over Potato-2024, complete with expected updates based on all the possible next-thoughts-you-could-think, reactions “them” might have, and so on. That’s, just, not the right way to understand what’s going on with the fleshy creatures described in this dialogue. And in general, it can be hard to have intuitions about strong evidence, and extreme numbers make human-implemented Bayesian especially brittle.
Now, to be clear: I think that debates about the rough quantitative probability of AI doom are worth engaging in, and that they are in fact (unfortunately) very different from debates about Potato-2024. Still, though, that old lesson looms: do not confuse your abstract model of yourself with yourself. The map is never the territory; but especially not when you’re imagining a map that would take a hyper-computer to compute. Fans of basic Bayesianism, and of number-noises, are well-aware of this; but the right dance, in practice, remains an open question.
As an example of a distortion I worry about with respect to the previous discussion: in practice, lots of people (myself included – but see also Christiano here) report volatility in their degree of concern about p(doom). Some days, I feel like “man, I just can’t see how this goes well.” Other days I’m like: “What was the argument again? All the AIs-that-matter will have long-term goals that benefit from lots of patient power-grabbing and then coordinate to deceive us and then rise up all at once in a coup? Sounds, um, pretty specific…”
Now, you could argue that either your expectations about this volatility should be compatible with the basic Bayesianism above (such that, e.g., if you think it reasonably like that you’ll have lots of >50% days in future, you should be pretty wary of saying 1% now), or you’re probably messing up. And maybe so. But I wonder about alternative models, too. For example, Katja Grace suggested to me a model where you’re only able to hold some subset of the evidence in your mind at once, to produce your number-noise, and different considerations are salient at different times. And if we use this model, I wonder if how we think about volatility should change.17
Indeed, even on basic Bayesianism, volatility is fine as long as the averages work out (e.g., you can be at an average of 10% doom conditional on GPT-6 being “scary smart,” but 5% of the time you jump to 99% upon observing a scary smart GPT-6, 5% of the time you drop to near zero, and in other cases you end up at lots of other numbers, too). And it can be hard to track all the evidence you’ve been getting. Maybe you notice that two years from now, your p(doom) has gone up a lot, despite AI capabilities seeming on-trend, and you worry that you’re a bad Bayesian, but actually there has been some other build-up of evidence for doom that you’re not tracking – for example, the rest of the world starting to agree.18
And there are other more familiar risks of just getting even the basic Bayesianism wrong. Maybe, for example, you notice that your beliefs have been trending in a certain direction. Trump keeps moving up in the polls, say. Now you’re at like 95% on Trump win. And you read a tweet like Connor Leahy’s, below, telling you to “just update all the way, bro” and so you decide, shit, I’ll just go 100%, and assume that Trump will win. Wouldn’t want to predictably update later, right?

Or maybe you hear some prominent doomer proclaiming that “sane people with self-respect” don’t update predictably, without clarifying about “in expectation” despite definitely knowing about this, and so you assume you must be unsane and self-hating. Or maybe you think that if you do update predictably, it should at least be in the direction of your currently-predicted truth, and you forget about cases like the waterfalls above.
In general, this stuff can get tricky. We should be careful, and not self-righteous, even when the math itself is clear.
9. Just saying “oops”
I also want to add a different note of caution, about not letting consistency, or your abstract picture of what “good Bayesianism” looks like, get in the way of updating as fast as possible to the right view, whatever that is.
Thus, for example, maybe you tweeted a bunch in the past re: “no way” on AI risk, and acted dismissive about it. Maybe, even, you’re someone like David Thorstad, and you were kind enough to quantify your dismissiveness with some very-low number.
And let’s say, later, your gut starts twinging. Maybe you see some scary demo of deceptiveness or power-seeking. Maybe you don’t like the look of all those increasingly-automated, AI-run wet-labs. Maybe it all just starts changing too fast, and it feels too frenetic and out of control, and do we even understand how these systems are working? Maybe it’s something about those new drones.
It might be tempting, here, to let your previous skepticism drag your new estimates downwards – including on the basis of the sorts of dynamics discussed above. Maybe, for example, if you had David Thorstad’s number, you’re tempted to move from .00002% to something like, hmm, 20%? But you say to yourself “wait, have I really gotten such strong evidence since my previous estimate? Have I been so surprised by the demos, and the drones, and the wet-labs? Apparently, I’m moving to a number I should’ve been less than one-in-a-million I’d ever end up at. By my previous lights, isn’t that unlikely to be the right move?”
But the thing is: it’s possible that your previous estimate was just … way too low. And more (gasp), that it didn’t come with some well-formed probability distribution over your future estimates, either. We should be wary, in general, of taking our previous (or our current) Bayesian rigor too seriously. Should “you,” above, refrain from changing her potato-2024 estimate quickly as she thinks about it more, on grounds that it would make her two-seconds-ago self’s Bayesianism look bad? Best to just get things right.
Of course, it may be that your previous self was tracking some sort of evidence that you’re losing sight of, now. It may be that your gut is skittish. You should try to learn from your previous self what you can. But you should try, I suspect, to learn harder from the actual world, there in front of you.
Here, to be clear, I’m partly thinking about myself, and my own mistakes. I said 5% in 2021. I more than doubled my estimate soon after. By basic Bayes, I should’ve been less than 50%, in 2021, that this would happen. Did I really get sufficiently worrying evidence in the interim to justify such a shift? Maybe. But alternatively: whatever, I was just wrong. Best to just say oops, and to try to be righter.
I’m focusing on people with very low estimates on doom, here, because they tend to be more common than the converse. But everything I’m saying here holds for people with low estimates on non-doom, too. If you’re such a person, and you see signs of hope later, don’t be attached to your identity as a definitely-doomer, or to the Bayesian rigor of the self that assumed this identity. Don’t practice your pessimism over-hard. You might miss the thing that saves your life.
Really, though, I suspect that respect for your previous self’s Bayesianism is not the main barrier to changing our minds fast enough. Rather, the barriers are more social: embarrassment stuff, tribal stuff, status stuff, and so on. I think we should try to lower such barriers where possible. We should notice that people were wrong; but we should not make fun of them for changing their minds – quite the contrary. Scout mindset is hard enough, and the stakes are too high.
10. Doing enough
"I imagine death so much it feels more like a memory…"
- Hamilton
“When my time is up, have I done enough?”
- Eliza
I’ll close by noting a final sort of predictable update. It’s related to the scans thing.
There’s a scene at the end of Schindler’s List. World War II is over. Schindler has used his money to save more than 1,100 lives from the holocaust. As the people he has saved say goodbye, Schindler breaks down:
I could have got more out. I could have got more. I don’t know. If I’d just… I could have got more… I threw away so much money. You have no idea… I didn’t do enough… This car. Goeth would have bought this car. Why did I keep the car? Ten people right there. Ten people. Ten more people. This pin. Two people. This is gold. Two more people. He would have given me two for it, at least one. One more person. A person, Stern. For this. I could have gotten one more person… and I didn’t.
Now, we need to be careful here. It’s easy for the sort of stuff I’m about to say to prompt extreme and unbalanced and unhealthy relationships to stuff that matters a lot. In particular, if you’re tempted to be in some “emergency” mode about AI risk (or, indeed, about some other issue), and to start burning lots of resources for the sake of doing everything you can, I encourage you to read this article, together with this comment about memetic dynamics that can amplify false emergencies and discourage clear thinking.
Still, still. There’s a possible predictable update here. If this AI stuff really happens, and the alignment stuff is looking rough, there is a way we will each feel about what we did with the time we had. How we responded to what we knew. What role we played. Which directions we pointed the world, or moved it. How much we left on the field.
And there is a way we will feel, too, about subtler things. About what sorts of motivations were at play, in how we oriented towards the issue. About the tone we took on twitter. About the sort of sincerity we had, or didn’t have. One thing that stayed with me from Don’t Look Up is the way the asteroid somehow slotted into the world’s pre-existing shallowness; the veneer of unreality and unseriousness that persisted even till the end; the status stuff; the selfishness; the way that somehow, still, that fog. If AGI risk ends up like this, then looking back, as our time runs out, I think there will be room for the word “shame.” Death does not discriminate between the sinners and the saints. But I do actually think it’s worth talk of dignity.
And there is a way we will feel, too, if we step up, do things right, and actually solve the problem. Some doomer discourse is animated by a kind of bitter and exasperated pessimism about humanity, in its stupidity and incompetence. But different vibes are available, too, even holding tons of facts fixed. Here I’m particularly interested in “let’s see if we can actually do this.” Humans can come together in the face of danger. Sometimes, even, danger brings out our best. It is possible to see that certain things should be done, and to just do them. It is possible for people to work side by side.
And if we do this, then there is a way we will feel when it’s done. I have a friend who sometimes talks about what he wants to tell his grandchildren he did, during the years leading up to AGI. It’s related to that thing about history, and who its eyes are on. We shouldn’t need people to tell our stories; but as far as I can tell, if he ever has grandchildren, they should be proud of him. May he sit, someday, under his own vine and fig tree.
Of course, there is also a way we will feel if AGI happens, but the problem was unreal, or not worth worrying about. There are costs of caution. And of course, there is a way we will feel if all this AGI stuff was fake after all, and all that time and money and energy was directed at a fantasy. You can talk about “reasonable ex ante,” but: will it have been reasonable? If this stuff is a fantasy, I suspect it is a fantasy connected with our flaws, and that we will have been, not innocently mistaken, but actively foolish, and maybe worse. Or at least, I suspect this of myself.
Overall, then, there are lots of different possible futures here. As ever, the Bayesian tries to live in all of them at once. Still: if, indeed, we are running out of time, and there is a serious risk of everyone dying, it seems especially worth thinking ahead to hospitals and scans; to what we will learn, later, about “enough” and “not enough,” about “done” and “left undone.” Maybe there will be no history to have its eyes on us – or at least, none we would honor. But we can look for ourselves.
To be clear: there are lots of other risks from AI, too. And the basic dynamics at stake in the essay apply to your probabilities on any sorts of risks. But I want to focus on existential risk from misalignment, here, and I want the short phrase “AI risk” for the thing I’m going to be referring to repeatedly.
Though, the specific numbers here can matter – and there are some cases where despite having low probabilities on doom now, you can predict ahead of time that you’ll be at least somewhat more worried later (though, there are limits to how much). More below.
Hopefully not more literally similar. But: a new thing-not-imagined-very-well.
Modulo some futurisms. Including, importantly, ones predictably at stake in AI progress.
“In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine’s Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time.”
Thanks to Katja Grace for discussion.
Some forecasts have self-fulfilling elements, especially with respect to Moloch-like problems. And there are questions about e.g. internet text increasing the likelihood of AIs acting out the role of the scary-AI.
See e.g. Scott Alexander here. Some of Yudkowsky’s public comments suggest this model as well, though his original discussion of “conservation of expected evidence” does not.
Here I’m indebted to discussion from Greg Lewis and Abram Demski.
.99*1 + .01*0 = .99.
Or put another way: you want to find the area that red occupies, which is the area of the first, smaller red box, plus the area of the bigger red box. Each box occupies a percentage of the area of a “column” (combination of white box and red box) associated with a hypothesis about GPT-6. So to find the area of a given red box, you take the area of the column it’s in (that is, the probability on the relevant hypothesis about GPT-6), and multiply that by the percentage of that column that is red (e.g., the probability of doom conditional on that hypothesis). Then you add up the areas of the red boxes.
Thanks to Daniel Kokotajlo for highlighting some of these dynamics to me years ago. See also his review of my power-seeking AI report here.
I added an edit to this effect.
Thanks to Katja Grace for discussion here.
Here I’m inspired by some comments from Richard Ngo.
Though: maybe it just works out the same? E.g., the average of your estimates over time needs to obey Bayesian constraints?
Again, thanks to Katja for pointing to this dynamic.
Ur-AI is currently winning the human/AI war by making our lives so rich, meaningful, and fun that fertility's dropped under replacement rate for half of humanity; cooler than Terminators, am I right? Thinking of them as our descendants takes some of the sting out of it.